Presence Protocol. a new way of building in high-pressure, low-trust environments.

Presence Protocol is a coordination model for systems that need to stay adaptive under pressure—whether digital, social, or cognitive.
It’s designed for situations where continuity can’t be guaranteed: where people drop out, machines break, roles shift, or memory fails. Instead of relying on fixed identities, centralised control, or consensus-driven logic, Presence uses pressure, memory traces, and behavioural coherence to keep things moving.
This project is for developers, protocol designers, and systems thinkers who are building tools for:
- Decentralised or schema-fragile environments
- Adaptive social systems (trauma-aware, non-hierarchical, peer-to-peer)
- Infrastructure that needs to recover, not just reboot
In plain terms:
Presence Protocol helps systems recover gracefully, adapt in real time, and remember what worked—without needing to be perfect, consistent, or always online. It replaces “rollback and retry” with “erode and re-enter.”
It’s not about control. It’s about coherence.
This post is to explain the core mechanics, use cases, and current architecture of the protocol.
I'm already building it, but would love some input if this sounds like a project that interests you.
If you're curious about how distributed agents can coordinate through shared pressure, compressed memory, and symbolic intent—you’re in the right place.
In plain terms:
Want to try wrecking a network with me and seeing what survives? haha.
Contact me here, or read the developer call out here.
Or, just read on about the project.
What It Replaces:
Consensus → with coherence (functional alignment under pressure)
Identity → with affordance (what a node can do in the moment)
Rollback → with re-entry (based on memory traces, not prior state)
Schema negotiation → with vector + residue logic
Declared trust → with relational pattern memory
| Traditional Model | Presence Protocol |
|---|---|
| Consensus | Coherence |
| Identity | Functional Affordance |
| Rollback | Memory-based Re-entry |
| Trust | Behavioral Trace |
| Shared Schema | Pressure Vectors + Residue |
Key Mechanics: How Presence Protocol Works in Practice
Traditional systems often assume stability, shared language (schema), and consistent participation. Presence flips that assumption.
It’s built for real-world complexity, where people or components join late, leave early, or change form entirely.
Nodes join, leave, or mutate dynamically.
Instead of requiring all participants to remain stable or even identifiable, nodes in Presence are expected to come and go. A node might be a person, a service, a bot, or even an ambient signal layer.
The system doesn't rely on fixed identity or static roles—it tracks what the node can do under pressure, not who it is. If a node drops out or changes form, the system doesn't crash; it adjusts.
Communication relies on directional pressure, not shared schema.
In conventional networks, communication often requires a common structure: you must "speak the same language" with agreed fields, labels, and formats. In Presence, communication is driven by pressure vectors—compact signals that indicate tension or need (e.g., “this node is overloaded,” “this function is missing”).
Nodes don’t have to agree on how data is structured; they only need to respond to pressure in ways that fit their local affordances. This enables schema-optional coordination, crucial for mismatched systems or multilingual agents.
Memory is distributed, not centralised.
There’s no central log or database. Instead, memory is stored in residue (compressed traces of what actions were taken under stress) and drift fields (ambient gradients shaped by historical pressure). This makes memory less fragile. If a node disappears, its memory isn’t gone—it’s left behind as a kind of environmental signal other nodes can use.
This design reflects a core insight: systems that rely on perfect recall are brittle. Systems that rely on shared traceability are adaptable.
Recovery is based on prior role performance, not resets.
When something fails, we don’t go back to the last saved state. Instead, we look at the role fingerprint—what function a node performed under similar pressure in the past—and allow it to re-enter if the current conditions align.
This removes the need for complex rollback procedures or state reconciliation. A node can say, in effect: “I’ve done this before. I know how to do it again.” And the system responds accordingly.
Change is introduced through symbolic negotiation, not force.
Instead of forcing every node to upgrade or interpret change identically, the system uses gesture bytes (small symbolic signals) and gatekeeper packets (special envoys of change).
These allow upgrades or shifts to be introduced gracefully, with room for legacy participation or soft failure. Change is a process, not a rupture—and symbolic negotiation creates time and space for nodes to adjust.
Where Presence would make a meaningful difference:
Schema-resilient APIs and distributed protocols.
APIs often break when two systems speak slightly different versions of a schema. Presence allows for schema-optional fallback—where nodes can communicate based on pressure and affordance, even if their schemas don’t match. This enables interoperability across loosely coupled or evolving infrastructures.
AI-to-AI coordination across non-interoperable models.
Different AI models often “speak” in different outputs, vectors, or logical structures. Presence enables coordination through resonance, not matching schema. One AI model can respond to pressure emitted by another—even if it doesn’t fully parse the source—because it’s tuned to pressure type, urgency, and direction.
Post-failure network reformation (graceful fallback).
Whether it’s a P2P mesh network, a supply chain system, or a crisis-response platform, things go wrong. Presence allows systems to erode (step back) and re-form based on memory traces, rather than trying to force a brittle system to continue. Nodes rejoin when they make sense again—not when an external controller demands it.
Cognitive design for trauma-aware social infrastructure.
Social systems—especially those supporting marginalized or trauma-impacted communities—often fail when they demand consistent performance, clear roles, or fast recovery. Presence offers a pressure-based, memory-aware way of navigating absence, return, and adaptation without penalizing irregular participation.
Mixed human-computer agent teams in high-pressure settings.
In emergency response, high-volume customer service, or dynamic moderation environments, humans and bots often work together. Presence allows them to coordinate not through command chains or task queues, but through ambient cues, drift fields, and role re-entry based on demonstrated behavior, enabling a kind of improvisational resilience.
Functional Benefits: What This Model Actually Enables
A runtime model for adaptive load management.
Presence enables systems to understand and respond to where the pressure is, without needing constant human oversight or static thresholds. Load isn’t just “how busy is this node”—it’s what kind of tension is present, and how it flows across the system.
Behavioural fallback when schema fails.
If two parts of a system don’t share a schema, Presence doesn’t halt. Instead, it falls back to pressure-based behavior: nodes respond to the intensity and type of incoming signals, not to whether they understand every field. This is essential for real-world interoperability.
Residue-traced memory for re-entry.
Rather than versioned snapshots or checkpointing, the system uses residue—small traces of past behavior under pressure—as a memory stack. This allows nodes to return to useful roles without needing to re-synchronize or be manually reinserted.
Symbolic gesture channels for upgrades.
Updates in Presence are introduced through gesture bytes—symbolic messages that signal intention (e.g., “this is a soft upgrade,” “this requires fallback,” “this is experimental”). This allows nodes to opt-in based on pressure fit, not just version compatibility.
Drift-field logic for decentralized task reallocation.
When nodes erode or exit, they don’t just vanish—they leave behind residue that shapes the drift field. Other nodes sense this and begin moving toward roles they’ve proven capable of performing. This is coordination by memory, not order. It allows systems to shift intelligently without requiring central orchestration.
For Developers.
If you're a developer interested in distributed systems, schema-optional design, or runtime models that prioritize adaptability over rigidity, Presence Protocol is ready for your input.
This isn’t a fixed architecture—it’s a set of primitives and behaviours for building systems that survive pressure, evolve in place, and coordinate without consensus.
You won’t be writing static APIs or hardcoded workflows—you’ll be working on things like pressure vector parsing, residue memory chains, gesture byte negotiation, and decentralised fallback mechanics.
I'm currently looking for early collaborators in these areas:
- Pressure Vector Modeling
Help design the basic structure for how nodes broadcast, sense, and respond to pressure vectors (load, mismatch, urgency signals) across a distributed environment. - Residue Memory Architecture
Prototype lightweight ways to store and share residue (behavioral trace data) between nodes without heavy logging or centralized databases. - Schema-Optional Communication Layers
Build or experiment with communication protocols where nodes can interact based on pressure and direction — not rigid schema matching. - Gesture Byte Negotiation
Design how nodes use small symbolic signals (gesture bytes) to negotiate changes, upgrades, or fallback without full parsing. - Drift Field Simulation
Help simulate how drift fields could emerge from accumulated pressure and residue—guiding node re-entry or task redistribution dynamically. - Coherence Detection Systems
Develop simple methods to observe, track, and validate coherence across a node cluster without requiring consensus or static snapshots. - Resilience/Fallback Stress Testing
Stress test small mock systems where participants intentionally drop out, mutate, or erode—to test how the protocol responds and reforms.
The spec is conceptual but implementable. If you're curious about real-time protocol logic, ambient coordination, or designing fallback instead of failure, reach out—we’re looking for collaborators to help take this from protocol to product.
If you'd like to see the working glossary of terms, please follow the link here.
Or, contact me here if you're interested in working on this project, I'd love to hear from you.
Thought Experiment
Three orchard-edge IoT sensors share a Presence mesh:
Node-A (soil-moisture probe) →
Node-B (solar weather station with Wi-Fi + LoRa) →
Node-C (green-house thermometer).
Mid-day, Wi-Fi on Node-B browns out; it hops to LoRa, keeping the chain alive.
Pressure vectors in flight
// 1 — normal operation
{ "origin":"A", "vector_type":"load", "magnitude":0.15,
"direction":"report", "timestamp":"2025-05-01T01:00:00Z" }
// 2 — Wi-Fi drop detected at B
{ "origin":"B", "vector_type":"mismatch", "magnitude":0.80,
"direction":"route", "timestamp":"2025-05-01T01:01:12Z" }
// 3 — rerouted via C on LoRa (hop-flag set)
{ "origin":"B", "vector_type":"latency", "magnitude":0.30,
"direction":"report", "timestamp":"2025-05-01T01:01:14Z",
"residue_reference":"res-0x9f2" }
Residue left behind
{
"residue_id":"res-0x9f2",
"role_fingerprint":"gw-relay-wifi",
"exit_reason":"link_down",
"re_enter_hint":"gw-relay-lora"
}
Node-C sees the mismatch vector, recognises the gw-relay fingerprint in the residue, and re-enters as temporary gateway until B’s Wi-Fi recovers.
No schema negotiation, no central broker—just pressure → drift-field → re-entry.
Questions I've asked myself through writing the protocol:
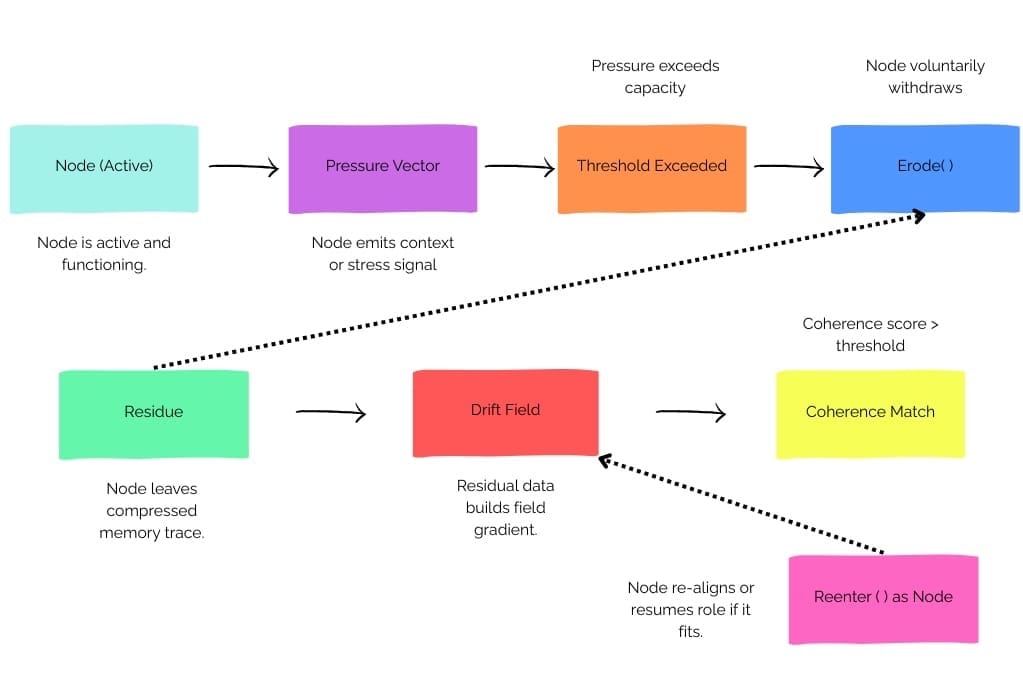
1. What does a node look like in software?
A node is an agent or peer with:
- A unique runtime context, not necessarily a persistent identity.
- A set of current affordances (capabilities under pressure).
- A memory footprint defined by:
role_fingerprint: a hash of behaviors performed under pressure.residue: a compressed log of previous role exits and outcomes.
- Status flags:
active,eroded, orre-entering.pressure_tolerance: thresholds before voluntary erode.
- Communication interfaces:
- Schema-optional input parsing
- Vector-based output signaling
This can be modeled as a stateful agent or service instance, ideally containerised or virtualised, operating within a shared protocol runtime.
2. How are pressure vectors expressed (e.g. metrics, logs, events)?
Pressure vectors are structured payloads like:
{
"origin": "node_id",
"vector_type": "load" | "mismatch" | "latency" | "urgency",
"magnitude": 0.0 – 1.0,
"direction": "affordance_tag" (e.g. "parse", "route", "hold"),
"timestamp": "2025-04-25T16:02:00Z",
"residue_reference": "residue_id"
}
These can be emitted as telemetry events, ambient gossip signals, or low-priority pub/sub messages across the mesh. They’re interpreted locally by each node to determine if/when to erode, redirect, re-enter, or mutate.
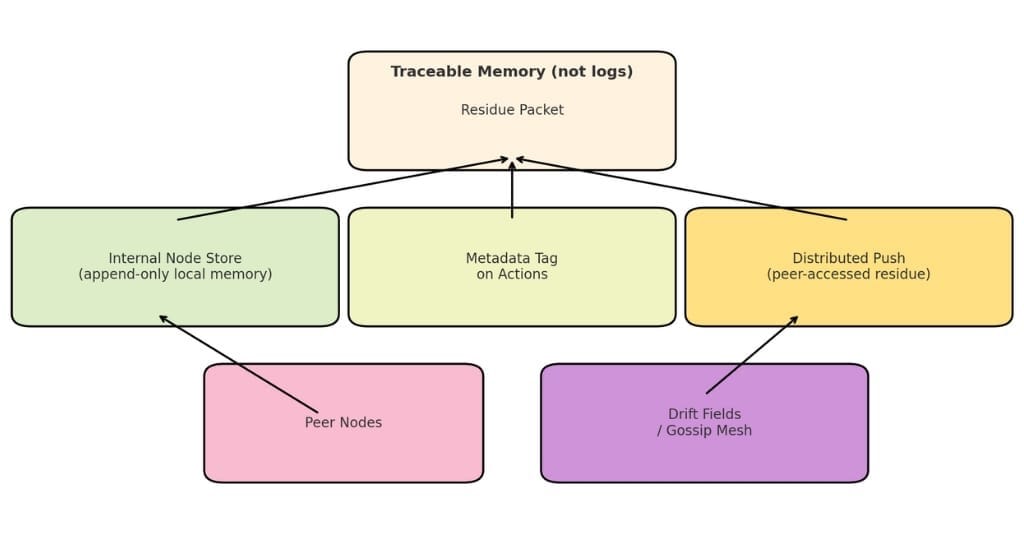
3. Is residue stored in logs? As metadata? As peer-scanned traces?
Residue is stored as:
- Minimal trace packets (key-value or hashed context pairs).
- Ambient metadata attached to node actions, accessible by neighbors.
- Logged locally in append-only format, but optionally shareable (e.g., when joining or re-entering).
Storage options:
- Internal: within the node’s local store.
- Distributed: as encrypted/minimally signed residue packets pushed to nearby peers or drift fields (low-consistency stores like gossip rings or sidecar mesh nodes).
Residue is not authoritative history. It’s traceable behaviour.
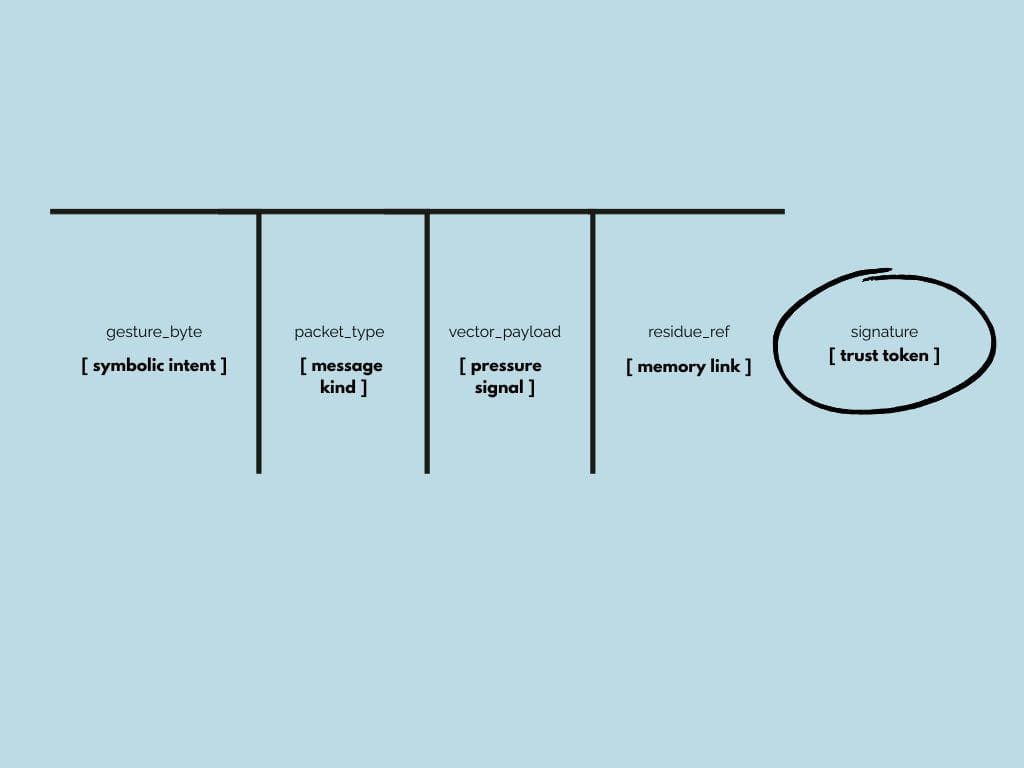
4. How does a gesture byte work in a message payload?
A gesture_byte is a symbolic, 1–2 byte field in a packet that:
- Signals intent, not data (e.g. “request upgrade,” “pause,” “handover”).
- Is pre-parsed before payload interpretation.
- Can be matched against a node’s trust map or role fingerprint for validity.
Example:
{
"packet_type": "upgrade",
"gesture_byte": "0x2A", // "slow bow"
"payload": {
"protocol_version": "2.1",
"features": ["schema-optional", "coherence-signaling"]
}
}
Nodes use gesture_byte handlers to determine whether to accept, delay, mask, or route packets based on symbolic interpretation—not full schema validation.
5. How would you observe or validate coherence?
Coherence is validated not by schema matching but by:
- Pattern recognition of successful behavior under load across nodes.
- Role fingerprint confirmation: comparing historical pressure-response traces.
- Quorum observation: nodes observe if at least
ntrusted peers have responded coherently (e.g., resolved similar pressure vectors within expected latency/margin).
Validation signals:
residue_chainalignment: matching past traces from similar contexts.coherence_score: a float between 0–1 based on recent pattern convergence.quorum_ping: ambient message to gather pattern-matched confirmations before engaging a re-entry or mutation.
These are tracked by lightweight observers (in-node or ambient services), not heavyweight consensus engines.
Potential Fault Lines I'm Addressing
Feel free to contact me about thoughts or solutions.
Area: Formal convergence guarantees
Pain Point: “Coherence score” is heuristic; an attacker could spoof pressure or residues to steer the group.
Why it Matters: Without some provable bound, safety-critical adopters (finance, aviation) will balk.
Mitigation Sketch: Define a minimal CRDT-style lattice for pressure vectors; require monotonicity so scores can only increase with corroboration.
Area: Observability & debugging
Pain Point: Residue is compressed; you risk forensic blind spots.
Why it Matters: Ops teams still need “why did node X erode?”
Mitigation Sketch: Keep raw traces for a sliding window, encrypt & age-off; surface an explain() API that expands a residue chain on demand.
Area: Gesture-byte namespace
Pain Point: Two teams might independently pick the same 0x2A for incompatible meanings.
Why it Matters: Version-skew fractures the layer.
Mitigation Sketch: Publish a tiny IANA-style registry or use a hash of (creator-id)
Area: Resource leaks in drift fields
Pain Point: Long-dead roles could keep attracting helpers.
Why it Matters: Could induce DDoS-like oscillations.
Mitigation Sketch: Add TTL decay proportional to vector magnitude; let decay rate be altered/tuned per deployment.
Area: Security model
Pain Point: Pressure vectors reveal node stress; an observer could target weakest links.
Why it Matters: Especially risky in adversarial meshes.
Mitigation Sketch: Permit encrypted pressure vectors with homomorphic comparisons (e.g., order-preserving encryption) when anonymity matters.
If you have questions that you'd like to pose, please send them here:
And I'll add my working and theory to this page as an ongoing document.
Thank you for reading. :)