The Ethereum man gave me a second riddle. This is how I solve it using metaphors about barramundi and crying in the cool-room.
So, in a bizarre twist of events, someone deep in the Ethereum world gave me a problem. I can imagine them no other way until proven otherwise.

I worked through it here:
Accidentally Reverse Engineered Ethereum's Business Model Whilst Making Jokes about Pythons Eating the Keys to your House.
I just want to reiterate, I did NOT have ANY prior knowledge of anything before I reverse engineered this.
Same with this next problem.
Because they didn’t send it to me directly, but through my friend who is a chef who knows I love being asked questions (because that’s how I write anything, question first, synthesis through essay writing) - they then sent me this the next morning:
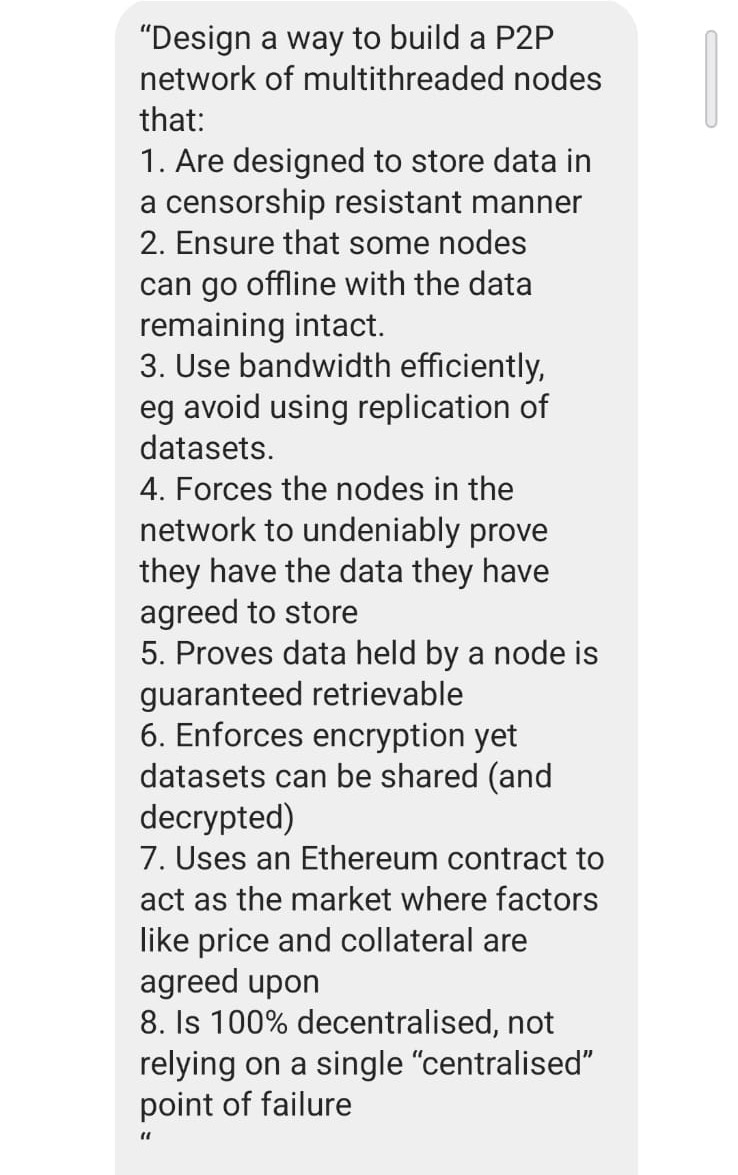
So I’m assuming their response was:
“Okay, first round passed. Second round engaged.”
It looks harder (mostly just longer) but I can tell this time, it’s explicitly within Ethereum logic.
Now, I don’t write about crypto. I didn’t even know how crypto worked until yesterday. This is not a “claim to genius”, it’s a message to all that are afraid of tech:
“You can reframe these difficult questions, overloaded syntax, by using terminology you do understand, and lived experience.”
I promise. I will help you do it. This is what this piece is for!
I’m not trained in systems design, or blockchain architecture, or any of this.
What I do have is a recursive cognition brain from trauma (lots of pieces on my Substack bout that, and they are NOT memoirs, they’re explaining cognition from the only perspective I have - my own - and with systems deconstruction).
My brain treats logic structurally, not symbolically — and when I’m given something impossible to parse, my brain doesn’t panic. Well, it used to, but not anymore.

The difference is mostly instead of thinking in a straight line, my brain defaults to mapping.
But mapping spatially, and responsive to pressure. Because I’ve been using AI and other programs not as a productivity tools, but as a resonant logic engines, it has helped me immeasurably in that I’ve learned how to design systems I shouldn’t be able to see.
Because I actually want a job in tech, I’ve decided to just post these as like, field reports, from someone with no credentials, solving a technical architecture puzzle by running it through the kitchen during service and listening to the metaphors that stuck.
So, here’s what happened when I treated Ethereum like a restaurant, data like a waiter’s handover, zk-SNARKs like social trust gestures, and decentralisation like a shift with no manager.
Everything we want to avoid right? Same with Ethereum apparently.

The question again:
“Design a way to build a P2P network of multithreaded nodes that: 1. Are designed to store data in a censorship resistant manner 2. Ensure that some nodes can go offline with the data remaining intact. 3. Use bandwidth efficiently, eg avoid using replication of datasets. 4. Forces the nodes in the network to undeniably prove they have the data they have agreed to store 5. Proves data held by a node is guaranteed retrievable 6. Enforces encryption yet datasets can be shared (and decrypted) 7. Uses an Ethereum contract to act as the market where factors like price and collateral are agreed upon 8. Is 100% decentralised, not relying on a single “centralised” point of failure”
Let’s begin.
So this is a movement forward from the original question, and now asking me to think inside the Ethereum machine.
This to me immediately reads as a technical problem but it is within the system of Ethereum’s logic, so it must abide to its ruleset / conditions within its container.
But before I do anything I must understand the syntax. Because I don’t know what the hell this question is asking because of it, but understand some of the other words. Like “act” and “failure”.
Lol.
Easiest way I can do this is clause by clause. Like someone slowly repeating steps but only moving forward when the previous is understood.
And because of how I do my working I’m just going to format this as readable instead of insane scrawl like physics lecturer lord going off on the whiteboard.

“Design a way to build a P2P network of multithreaded nodes that:
Okay so what is P2P in this context?
P2P
- A P2P network is a system where each participant (or peer) communicates directly with other peers — no central server or controller.
- Everyone’s both a server and a client.
- No central unit, information passed between. (threads im assuming?)
- But, everyone must take partial responsibility for the system’s function. There is no central fallback.
This I already know from a theoretical stand point.
This is just working in hospo.
Example 1 Peer is FOH.
Example 2 Peer is BOH.
Example 3 Peer is Customer.
Example 4 Peer is Till.
They're communications between each other (Peer to Peer).
Customer to FOH.
FOH to Till.
Till to BOH.
BOH to FOH.
BOH to Till (reading).
Customer to FOH.
Customer to Till (payment)
And so on.
There’s no centralised “point” or like, singleton (hahaha probs wrong but like, that’s my brain soz!) directing this. There’s just shared understanding of roles and available actions.
Each peer interacts based on context.
So:
- Distributed responsibility (roles)
- No single point of control (gotta work together team! yeesh)
- Direct communication paths (do not hide info, distribute sensically otherwise you’re getting yelled at)
- Emergent coordination (behave as chaos is expected, not avoided/encountered randomly)
- Contextual trust (e.g. BOH trusts tickets from FOH, not from customers directly)
So what I’ve learnt is that a P2P network doesn't mean all peers are “equal”— it just means they can all act directly on the system without needing a master controller.
Explains why we all hate top-down management right?

It looks like also in P2P networks, peers have different specialisations, just like BOH, FOH, and Customer. But they all need to have at least some consistent executions otherwise system doesn’t hold up:
- Start or initiate actions
- Store or transmit information
- Are part of the system’s function
So they’re all peers, different functions, implicit trust.
So what that means is there must be social protocol and spatial proximity (restaurant environment, sections).
That’s how service works.
- Formalise trust (you can’t “vibe” who’s FOH)
- Handle failure (e.g. FOH walks out mid-service = node offline)
- Route around absence (if FOH is down, how does Customer get food?)
So it’s like pressure mapping in a way in this system, accommodation for that?
That makes sense to me.
Next word.
Multithreaded

- Learnt this last night from the previous problem.
- thread is a lightweight unit of execution — like a mini-process. In singleton land, it was “creation pattern”
- Multithreading means a single node (participant in the network) can do multiple things at once (e.g., store data, respond to requests, prove possession, etc.) This was like, the core issue of the previous problem.
- Threads can run in parallel inside the same machine.
Okay so using the restaurant example:
The “flow” is just the routes on the way to the node, or completion of “task”.
So FOH taking an order from customer (single node doing a multi-threaded action - recording order, thinking about what they’ve ordered, responding / asking for allergies, noting and rearranging that information, keeping personality whilst doing so, also standing - body language / tone).
Multiple FOH can be tableside whilst this happens.
A FOH is taking an order, another is filling the customers water up.
In tech, this is explained like:
- Input Handling: receiving the order
- Parsing: interpreting it (e.g. allergies, special requests)
- Contextual Awareness: tone, posture, social cues
- Output Construction: summarising, confirming
- Background Processing: remembering other table needs, eyeing water levels, etc.
So they’re just small, contained tasks that operate semi-independently, but share memory/state (in this case, the FOH’s body/mind/environment).
So multithreading is doing many related things, simultaneously or with enough interleaving that it feels simultaneous.
Sounds like literally the base requirement for a hospo trial.
“Hold three plates whilst someone is trying to talk to you and you also are dehydrated.”
Very good. :|
But if there’s interruption, cause your friend has asked for a stable P2P multithreaded system:
More specific examples, so let’s say a FOH is:
- Mid-order when the customer changes their mind
- Simultaneously thinking about the table that’s been waiting for the card machine
- Trying to remember the wine list change from yesterday
That’s when thread conflict happens. Memory access is contested. Side effects appear.
In programming: race condition.
In hospo: forgetting to ring in the main.

Hm so…
When one FOH is overloaded (mid-order, mentally tracking card machine, wine list update), the system stabilises if:
- Another FOH notices and picks up the card machine task.
- A manager quietly re-prints the wine list and sets it down. (Lol. Okay. Guess tech is also unrealistic)
- The kitchen pings the server to confirm missing mains.
This is the P2P network coordinating via partial failure (not sure of the correct word?) and observational awareness, even though no one has a master task list.
In technical systems, as I understand, this would be:
- Load balancing
- Health checks
- Distributed fallback triggers
Or like - cache validation? Not sure.
I only know that again from ChatGPT trying to riddle me with that computer systems question about hardest things in computing.
For those interested and non-computerey, that is this:
“There are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors.”
or
“There are 2 hard problems in hospitality, remembering specials, rotating sections fairly — wait — whose table is this?”
Back to learning.
So you’d have to account for in the systems structure peer nodes sensing imbalance and redistribute load or provide memory reinforcement
But in hospo that’s only possible like:
- Other peers are idle enough to intervene
- Signals of distress are legible (body language, lateness, errors)
So that can fail…hmmm…
If the overloaded FOH can’t be helped externally, the resolution becomes internal triage:
- They decide: finish this order first → forget the wine list for now → get the card machine once order’s sent.
- This is re-prioritisation under pressure, based on real-time evaluation of system stakes.
In programming terms:
- A thread encounters a conflict and gives up or lets pass, blocks, or queues a task because it sees the conflict as “more urgent”.
- Or the system has a scheduler that dynamically prioritises based on urgency, latency, or resource access.
So a single node must self-regulate based on task visibility and risk hierarchy.
You must breathe first, cry later.
This I imagine only working clearly:
- Tasks are clearly scoped
- Stakes of each task are known
- There is internal logic to fall back on (like “always serve first before correcting wine list”)
I imagine this is probably closer to what’s accounted for in computing, because it is a contained system, not an infinite one? No program can have an infinite dataset, because it’s built, not like “space”.
So, in a contained system, if the FOH can't defer and no one helps?
- Mains don’t get fired.
- Customer gets wrong wine.
- FOH burns out.
- System trust drops.
So like data corruption, failed write, inconsistent state. Not good.
So survival only happens when":
- Peers can observe and act without being told.
- Nodes have internal scheduling logic and override rules.
- Tasks fail gracefully and can be retried or offloaded.
I feel like I need to come back to this. I’m getting distracted as I learn. Or maybe it will be relevant later.
Probably.
I think this problem is intentionally complicated.
Lol.
Next word.
I kind of understand this already because I had to use it to make the other words make sense. But!
Nodes
- A node is one participant in the network — a computer, a person, a machine, anything running the software.
- In this question: each node in the P2P network is multithreaded, meaning it's capable of handling concurrency, not just single requests in a queue.

This is back to the singleton thing, I’m going to pull something from there I remember:
threads and locks, functional programming, separating identity and state, actors, sequential processes, data parallelism, and the lambda architecture.
Are concurrency programs. (Blessed lambda)
Looks like all of this applies to this scenario.
Okay I understand what I am working with in this system. I can move on.
Next clause:
1. Are designed to store data in a censorship resistant manner…
So censorship requires, one node not having the like, overall potential to override things inclusive of:
- Removing, altering, or preventing access to data
- Stopping other nodes from sharing or storing
- Deciding which data “should” or “should not” exist in the network
That’s literally the definition of what hackers do to break systems like this.
So it’s about making it secure from that, but also secure from internal breakage, accidental, by the peers themselves.
It’s about making storage and access immune to ANY intervention.
So in this system I need to design it in a way:
- No one peer controls the data’s accessibility
- No central registry can be tampered with
- No upload can be revoked by third parties once distributed
- No peer is forced to identify the data's content as “good” or “bad” before storing
I mean, after I did the question yesterday, I was asking ChatGPT to give me riddles to explore this reverse engineering practice as I found it extraordinarily useful for my own understanding.
One it presented was the logic for Zero-Proof Knoweldge systems, and what I see here, felt adjacent to what I learnt.

I understand from an Ethereum perspective, that this is where they have a key advantage - and that ZPK’s are actually what DIFFERENTIATE between cryptocurrencies. Well, a large part of it anyway.
Explained, hey all need their own way of maintaining their function which is decentralised transferral of currency (in this simulation) - and this is just Ethereums way of defining themselves.
I understand that ZKPs aren’t the only way to be censorship-resistant, otherwise that would risk the systems being far too easy to corrupt. Also, it provides severe risk for internal actors to corrupt it even accidentally, as the knowledge would be far too accessible if monopolised.
I think unfortunately I have to look up some differences between crypto things and I really hope my life on the internet isn’t permanently altered because of this e.g. getting random ads or videos from crypto people - but, c’est la vie - their systems are kinda poetry, I mean, I’m fully in aren’t I?
Thank you Ethereum person for this problem to help me be less judgemental :)
So, from forum trawl, bitcoin seems trustless, but mostly transparent. Everyone can see the full ledger.
Zcash and Mina Protocol centre ZKPs. Their whole networks rely on them for privacy and verifiability.
Monero uses ring signatures, another kind of privacy-preserving mechanism (not ZKP, but adjacent in goal).
That looks hard. I do not like the pictures I see. They make me feel blind.
Okay, so, importantly:
Ethereum is programmable and modularly private. It can optionally use ZKPs.
Mmmmmmmmmmm so where bitcoin is a calculator, Ethereum is a computer.
And privacy in Ethereum is not by default — but by design, when you want it.
It’s opt-in, layered, and context-dependent.
Cool.

So it doesn’t really matter what the goal is really because they all technically have the same goal: provide value and safety to the internal system.
it’s a proof model that you need to design — how you establish trust, privacy, and consensus — is what distinguishes crypto projects more than their “currency” features.
So I need to look at this question as building a trust architecture as opposed to purely “functional”.
It’s like, freedom of presence in the system’s ontology, as opposed to “freedom of speech” because that would undo the system.
OKAY moving on.
2. Ensure that some nodes can go offline with the data remaining intact.
Back to hospo!
- 1 FOH person calls in sick.
- Service still needs to happen
- tables still need to eat.
- orders need to get fired.
- wine list still needs updating.
What options do you have to continue?
This is something that is unquestionably catered for in hospo, so what I can think of is this:
- Other FOH were already copied in on their key duties (e.g. wine update, table allergies, VIP notes).
- Menus or booking notes are stored in shared systems, not in someone's head.
So there’s always PARTS of a service covered when nodes go offline.
But there’s also the understanding that if one is offline, the others will need to load tasks, but they’ll also have to work FASTER.
So you’re absorbing pressure, but they also have to account for scale and strain that comes with that.

AH so i understand why the next part is this!!!!!!!!!!
3. Use bandwidth efficiently, eg avoid using replication of datasets.
More requests / More bandwidth usage / More memory pressure / Higher chance of new failure
And that last part of 3.
Magic. In hospo metaphor it’s DOUBLE HANDLING.
Multiple people trying to accommodate for the loss and just doing it because they know it’s missing from the system because of the offline node and there’s no time to accommodate “scheduling” or “specific nodes for specific tasks” under pressure and scaling.
FOH 1 goes offline. Everyone else jumps in.FOH 2 prints the same ticket.FOH 3 grabs the same bottle of wine.FOH 4 runs the same explanation to the table.
SO
- Bandwidth = wasted motion
- Data = duplicated (orders, effort)
- Memory state = fractured
- Outcome = chaos
PTSD triggered. Whole system offline. Lol.

So in a perfect world we need:
- Coordinate without replication → Only one node restates the table’s order→ But all others know that someone has — without doing it again
- Store fragments → One FOH knows dietary info, another knows wine recs→ Together they form the full picture, but no single FOH has to know everything
- Rely on flow/guidance, not duplication → If FOH 1 is gone, table 3 gets rerouted to FOH 2 with context→ Not “let’s all go check on table 3” → It’s “now you will check table 3, and i will talk to chef”
- Avoid panic reflexes → System assumes absence will happen→ So it doesn't overreact when it does
PTSD triggered again.
Systems failure.
Server fire.
Everyone crying.
Not enough space in cool-room.
4. Forces the nodes in the network to undeniably prove they have the data they have agreed to store
This immediately reminds me of briefing or a handover.
A briefing is NEVER a static— it’s a performance of memory, trust, and protocol awareness.
When FOH does a shift handover:
They don’t just say “I know what’s going on.”
They have to demonstrate knowledge, otherwise there’s no movement in the system.
“This table is a coeliac, this one is waiting for a birthday dessert, this wine is 86’d.”
The team knows they have the data because they can answer dynamic questions in context. But this data isn’t actually like, proving anything e.g. the nodes “tasks or sequences”, it’s just showing they can produce memory, and therefore are reliable.
That feels logical, because the whole thing is about proof of PRESENCE not proof of fact. Like only that node will know that information because they were PRESENT in CONTEXT of the handover.
In handover, no one cares what you say you know.
It’s more about the fact that you can:
- You can reconstitute contextual fragments
- Under challenge
- In real time
- With other peers around acting or offline (crying in coolroom)
So,
“I am the kind of node that can be trusted to hold data reliably, because when prompted, I perform its structure without needing to reveal its full content.”
If someone can’t answer “what’s 86’d?”, trust collapses.
If someone says they know a table’s allergies but can’t recall when asked?→ The system cannot route memory through them anymore.
Lol it’s like social ZKP.
Hospo is crypto.
Hoooly shit hahaha.

5. Proves data held by a node is guaranteed retrievable
Okay so before is:
“I can show I have the thing.”
Now this is:
“I can guarantee I can give you the thing, when asked, intact.”
So like, in handover you wouldn’t say:
- Fish is 86’ed
In a seafood restaurant where there’s multiple types of fish and dishes that could be applied.
A node that says:
“I have the data!”
Or
“It’s fish!”
Isn’t useful unless it can also:
“Produce the exact segment, on demand, uncorrupted, with proof that nothing’s been lost, altered, or obscured.”
Or
“Barra is on 2 portions, sections already sat just now, so consider it out as safety when you next spiel.
Chef says that if people ask, sell the whiting. Smaller portion, but similar in texture. Also, costs more - more money. Everyone in my section already knows barra is out and has been recommended whiting, so don’t worry about letting them know.
Maybe just double check when you take their order that you let them know “so my colleague told me they’d let you know about the menu, sorry for the barra, but who’s going to try the whiting?”
You’re not just asking:
- Do you remember?
You’re asking:
Can I access it through you?
Can I rely on the outcome being legible?
Does your stored memory translate into shared delivery?
So when communicating the handover, or like, passing from node to node it needs to be:
- Fragment or segment-specific (node tasks so they don’t overload)
- Forward-moving (doesn’t interrupt the system)
- Pressure-resilient (customers re-asking or getting angry about no barra or testing you about the OOS barra even though they know)
- Reputation-preserving (we are one as FOH lol)
- Embedded in relational trust (“my colleague told me…” because it’s a standard of service that FOH build trust with node or peer (customer) otherwise the system would have already broken, and the handover must include damage control)
So data wise or like, in this system design:
The data is not just intact — it’s usable in context by other peers.
AH! So this is about MOTION. :)
Again, not truth as “correct” but truth as “must move” and “be present”
Truth is presence,
and presence is not static.
It’s a structure’s ability to re-enter itself without breaking.
Lit. I love this problem.
Pure systems / structural navigation in reverse.

6. Enforces encryption yet datasets can be shared (and decrypted)
Okay, this is need to go understand essentially what encryption looks like in Ethereum but also generally going off the basis that:
“Make this unreadable to everyone — until it must be read.”
“Make this private — yet still movable, portable, usable, and provable.”
Okay so description general:
“Cryptocurrencies stay secure by relying on modern asymmetric encryption methods and the secure nature of transactions on a blockchain. Cryptocurrency holders use private keys to verify that they are owners of their cryptocurrency. Transactions are secured with and blockchain encryption techniques.”
Eh. Not so helpful. Too general.
Again, I think I learnt about this last night when I was asking chatgpt to give me riddles to solve.
I learnt about hashing and lattice structures, mainly because I didn’t understand how this encryption worked when I was able to understand the following riddle:
I just copied it from my ChatGPT as it was presented:
THE PROBLEM:
The Labyrinth and the Firefly
You are inside a massive underground labyrinth. Somewhere in the middle of this maze is a single firefly in a jar. You know exactly where it is. I do not.
You claim that if I give you any valid starting location inside the labyrinth, you can, blindfolded, walk through a series of doors and tunnels and end up with your hand on the firefly jar — without telling me where it is.
But I don’t want to see the path or the jar. I just want to be convinced that you actually know where it is.
To prove this to me without revealing the location of the firefly, we invent a protocol:
There are thousands of identical doors scattered throughout the labyrinth, each with a button and a microphone.
Each door connects to a fork — and each fork leads to either:
A dead end
Or the next correct turn toward the firefly
Each time I pick a door, you must press the button and say only:
- "Left"
- or "Right"
You must do this for 100 randomly chosen doors, and you can’t lie even once — or I’ll know.
If you answer all 100 correctly, I still won’t know where the firefly is, but I’ll know you’ve got some way of consistently reaching it from all valid routes — which is something only someone who knows the layout could do.
🧩 YOUR TASK:
Design one additional layer to this protocol that would:
Make it harder for a liar to guess their way through
But still not reveal where the firefly is.
If you want to have a go at the riddle, I’ve put my working below this picture of Bowie in Labyrinth to not spoil it :)

My working:
“okay so, if I know the labyrinth, then I know the dimensions of the labyrinth. so I would calculate the furthest possible distance from the firefly, and then I would treat every time I landed as such. and then eventually I would hit the firefly? or, does that not account for the direction im facing. if im blindfolded are the doors like, one after the other? like are the doors equidistant from each other and always like, leading forward? or perceived forward?
I feel like in my head well, isn't it like, if it's not there, so therefore it must be somewhere else. so I just say not here, and then keep going until i have to say “here” because that’s where it is, then the verifier knows i know where the firefly is - because im in the room with it.
Regardless, the easiest solution, a protocol could be that at every 25th door, your personal orientation will change direction randomly”
After working through this problem, ChatGPT that I was working through the logic of ZKP’s but specifically what I learnt is I was just providing or working within the nature of a:
zk-SNARK.
I also learnt what
zk-STARK was.
They have core differences, but Ethereum context they use a combination of both of these, which makes sense because you need to facilitate
- P2P in contained environments (between individuals)
- P2P overall (between the system)
Both are used in different layers and applications and sometimes in tandem. Which makes sense, because trust is programmed in as I found out before and about presence, not single source of truth.
And that allows for:
- Private, fast, small transactions
- Massive, trustless, system-wide proofs
- zk-SNARK: “I can prove my part fast, with minimal bandwidth.”
- zk-STARK: “We can prove the whole state at scale without any initial secrets.”
So like in hospo:
SNARK = FOH proving to BOH they know a table’s allergy, quickly, during a busy service
STARK = System-wide audit that no allergy order was ever wrongly served, and no one had to trust a hidden process at the start.
Smart. Well, not really. Just necessary.
This is Lewis Carrol’s Snark. Lol.

7. Uses an Ethereum contract to act as the market where factors like price and collateral are agreed upon
Okay now comes the money part.
The whole thing is that it’s “fuck you money” with bitcoin. So it’s like on surface level anti-cap, but it’s not, cause it’s still just trading.
More like smart mafia.
So it’s like what are the terms and conditions that you can participate in the system we are designing.
“what does it cost to be a node?
What do you earn for serving?
What happens when you fail?”
I don’t know what an Ethereum contract is. I will look it up.
This is where I went for reference: https://ethereum.org/en/developers/docs/smart-contracts/
I understand that with Ethereum, a smart contract is just a public, permissionless standard for performing and enforcing a deal — with no human intervention.
Node-work.
The only way I can understand this is again, through hospo analogy and it looks similar to how tips are regulated.
Tip scaling systems are kinda like smart contracts in that they:
- Remove managerial discretion from distribution
- Encode the rules of reward in a visible, fixed system
- Automate fairness by formalising contribution or presence
So like compared to Ethereum context:
Input
Completed task, proof of storage
Hours worked, role type, or points-per-shift
Collateral
Staked ETH or slashed token
Tip credit penalties (e.g., lateness, no-shows)
Reward Function
Logic-based disbursement: if complete → pay
Tip pool divided via logic: hours × role weight
Automation
No human decides payout
Payroll or POS auto-distributes
Transparency
Code is public, visible to all
Staff know the formula ahead of time
Permission Proven
Anyone who meets terms can participate
Any shift-worker who clocks in plays by same rules
Penalties
Failed proof = loss of collateral
Docked share for infractions
Composability
Contracts can call others
Tip logic can integrate with POS, rosters, etc.

So:
- The price = what users pay to use the system (store or retrieve data)→ Like a customer paying their bill.
- The collateral = what providers lock up to prove they’re trustworthy→ Like a staff member staking their share in the tip pool, which they lose if they disappear or mess up. E.g. being moved on a tip scale to reflect this.
- The market (smart contract) = the neutral middle ground that checks:Did you store the file?Were you online when called?Did the user get their retrieval?→ And then automatically pays or deducts you, like a tip jar that knows who really showed up.
In hospo:
Customer pays $500 bill. 10% ($50) enters the smart contract pool. Staff are all nodes — each has collateral in (via hours, reputation, or literal stake)The system tracks:
- Who was there
- Who served which table
- Who completed their role
Then auto-distributes tip sharesIf someone abandoned their section mid-service? Their tip stake gets slashed and redistributed.
8. Is 100% decentralised, not relying on a single “centralised” point of failure
Well this is just an aggregation of everything that’s been looked over so far?????
Or is it a trick????
It feels like it’s asking:
“Do all the parts add up to something that survives without a centre?”
I’ll look over:
Censorship Resistance
No node can alter, suppress, or gatekeep access to memory, because presence is distributed structurally — not subject to approval.
Offline Node Tolerance
Tasks and memory are fragmented across peers, so if a node goes offline, pressure is absorbed without collapse.
Bandwidth Efficiency
The system avoids replication by assigning unique, contextual tasks per node — preventing double handling under stress.
Proof of Possession
Nodes prove they hold data not by showing it, but by behaving in ways only a holder could — like social zero-knowledge proofs.
Guaranteed Retrievability
Data isn’t just held — it’s delivered, intact and legible, in motion, under pressure, when it actually matters.
Encrypted Yet Shareable
Knowledge is encrypted until provable need, with zk-SNARK/STARK logic enabling private performance without exposing content.
Smart Contract Market
Participation rules — price, collateral, reward, and penalty — are codified via smart contracts, not enforced by hierarchy.
Total Decentralisation
Each clause eliminates central fallback: the system survives absence, enforces trust, distributes pressure, and rewards motion — meaning decentralisation isn’t added at the end, it’s what remains after every central dependency is removed.
That means:
“Design a way to build a P2P network of multithreaded nodes that:
1. Are designed to store data in a censorship resistant manner
2. Ensure that some nodes can go offline with the data remaining intact.
3. Use bandwidth efficiently, eg avoid using replication of datasets.
4. Forces the nodes in the network to undeniably prove they have the data they have agreed to store
5. Proves data held by a node is guaranteed retrievable
6. Enforces encryption yet datasets can be shared (and decrypted)
7. Uses an Ethereum contract to act as the market where factors like price and collateral are agreed upon
8. Is 100% decentralised, not relying on a single “centralised” point of failure
“
Yes? I have done this?
If yes, I accept the position anywhere, anyone reading this in tech (in particular, AI)
I want that for my brain because if this is what you guys do I am so keen for more riddles.
And more learning.
And more building systems!
Thanks for reading :)
